Most distribution platforms were something else at the beginning. Features such as a background process that speeds performance and a queue that handles an increase in demand helped the emergence of the distribution system. With time, the system became asynchronous, working within multiple processes and services.
Some benefits of these additional features are improved response and better flexibility. These advantages have hidden challenges. Some of the difficulties are in understanding reliability as failures outgrow a single request or service. This problem affects many teams. Although the technology for asynchronous systems is fully developed, creating trusted systems that can withstand the increase in complexity remains a challenge.
A queue creates new failure boundaries
Failures in traditional applications are always sudden and visible. The result of a request is easily traced because it either fails or succeeds.
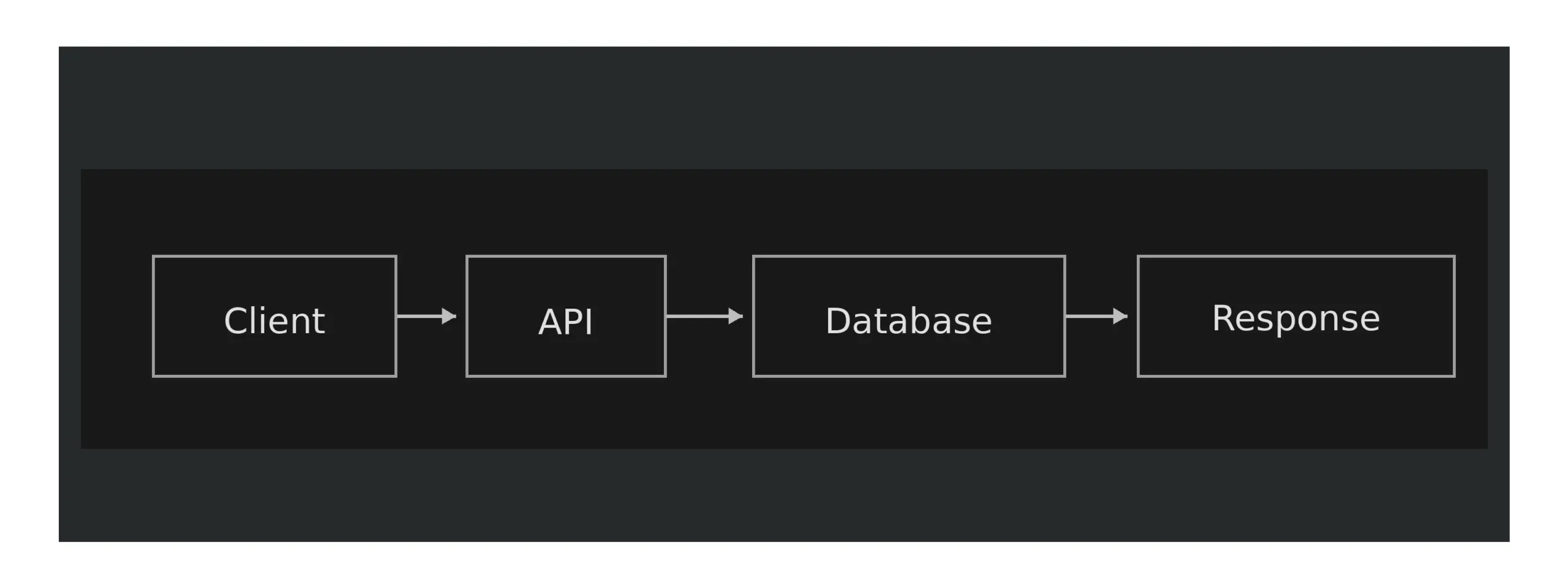
Asynchronous platforms show the difference between actions and outcomes. This enables work to be shared or processed independently of the previous request and introduces new failure boundaries.
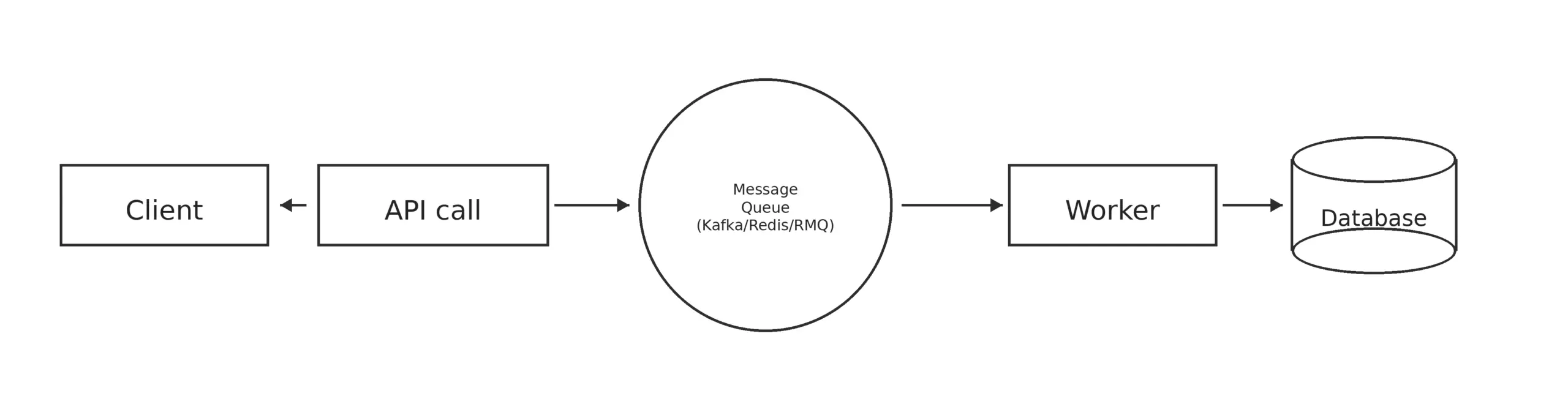
A workflow can fail in a background process after starting successfully. Also, the date may arrive late, and some parts can temporarily reject the system.
Went retries bite back
Sometimes, retries are perceived as a trust feature, and in most cases, they are. When failures occur, the challenge begins. A function of retries is to increase activity across systems during a temporary crisis. Recovery mechanisms can create additional pressure on services that are already stressed when there is an increase in workloads. An issue that was small in the beginning can grow into something bigger. An issue that started as a little can grow into a bigger incident, even after starting successfully.
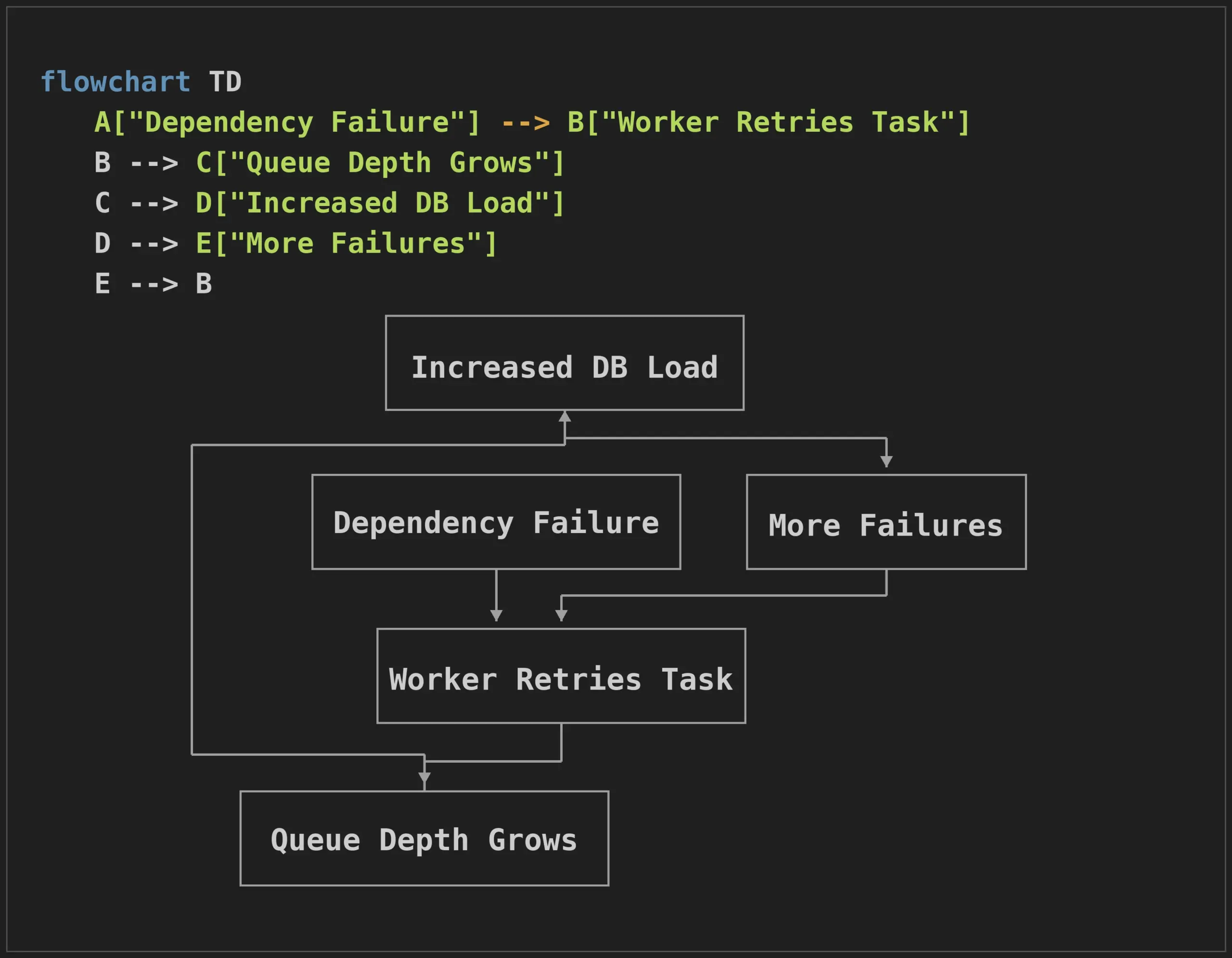
Trusted systems handle retries as a controlled recovery feature. This is because it is expected that recovery will have instability.
Exchange and the myth of “just use a queue”
A common misunderstanding is that a queue solves trust challenges. This is incorrect because the flow of the message is part of the system, in reality.
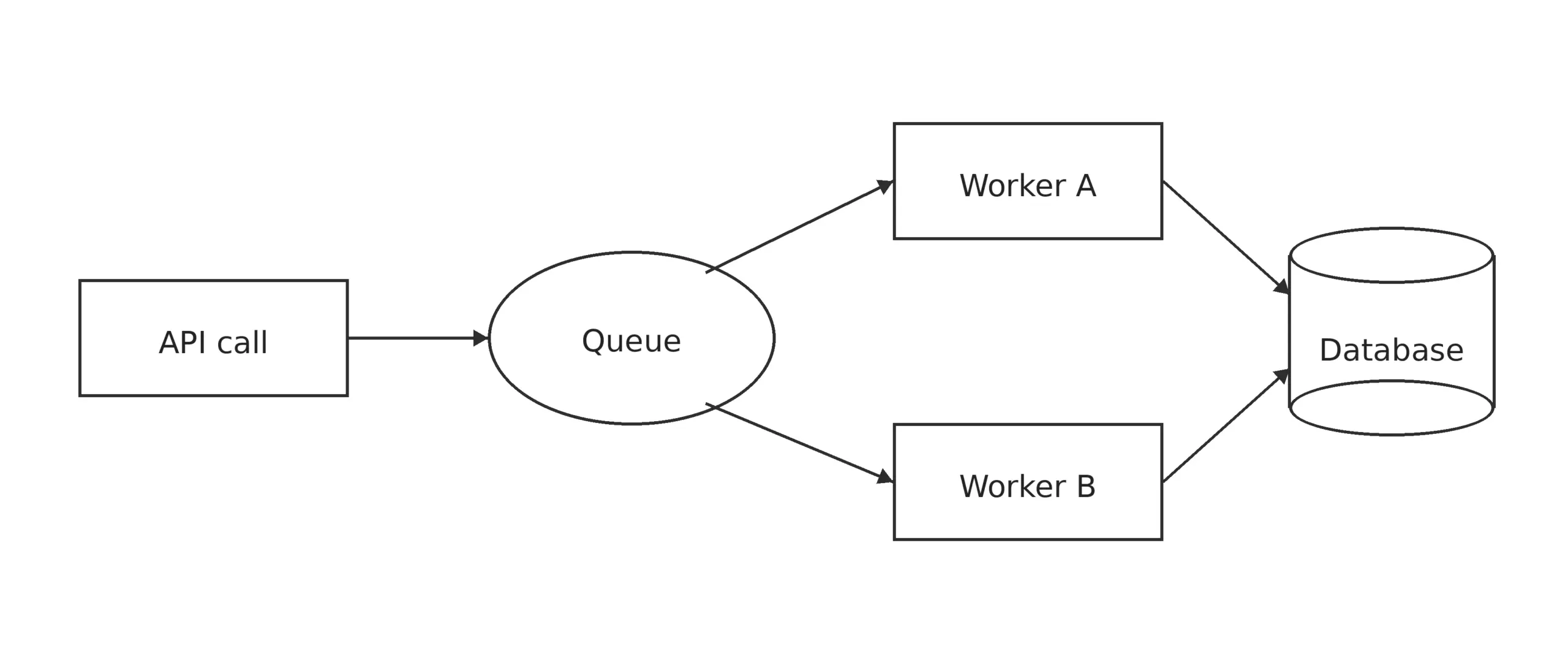
The features that govern how information flows between systems become important as changes continue to occur. Workflows that were poorly designed can cause operational blind spots and hide failures. The required adjustment was changing the pipeline:
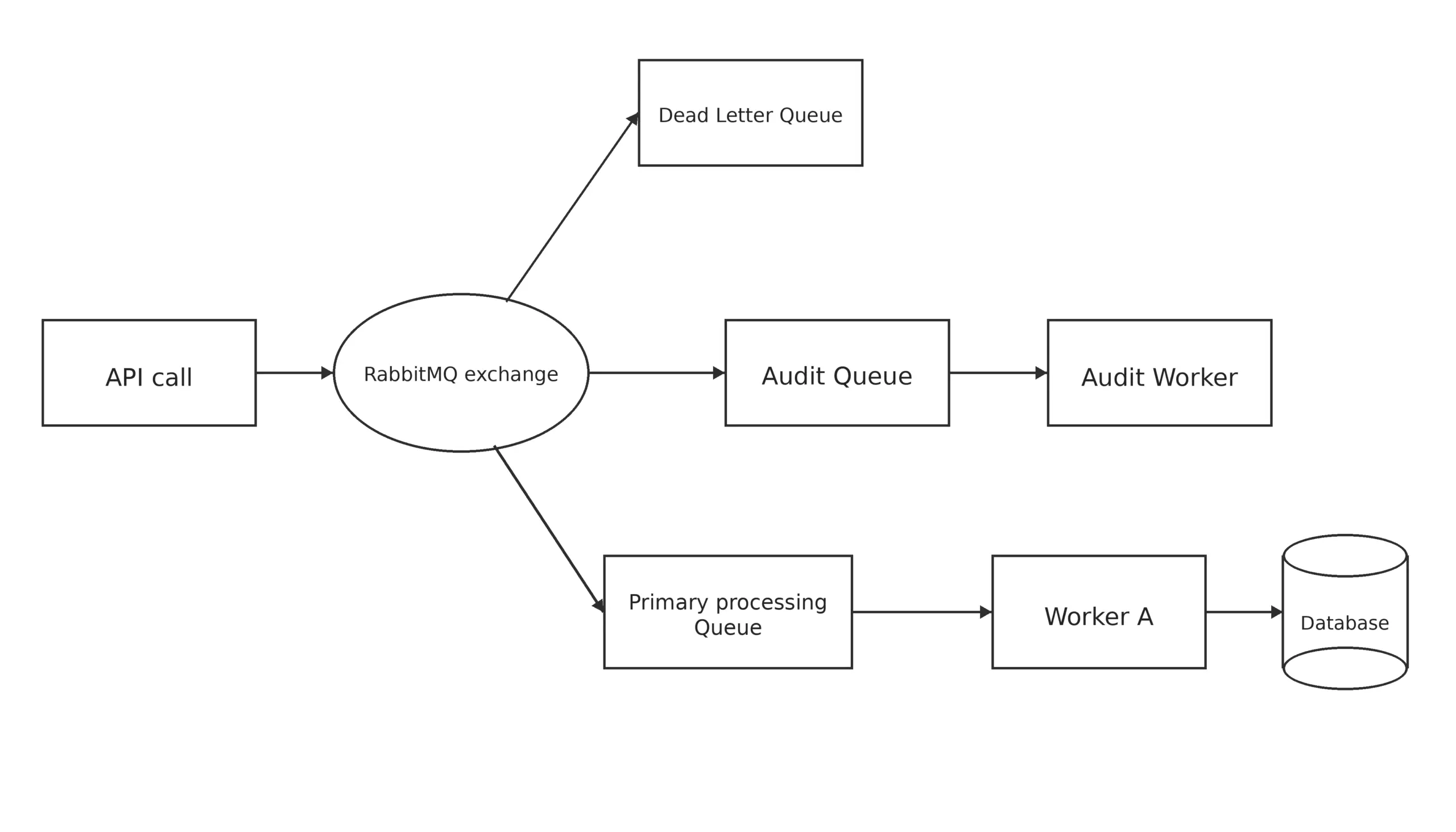 Well-built routing mechanisms provide clear ownership and bring visibility into work progress within a system. This means that systems are important in technology.
Well-built routing mechanisms provide clear ownership and bring visibility into work progress within a system. This means that systems are important in technology.
Idempotency and controlled retry semantics
Distributed systems have to assume that operations can occur several times. Network interruptions and system failures can lead to the repeated execution of one action. Repeated processing can cause inconsistent outcomes and reduce trust in system behaviour, without preventive actions. Trusted systems are designed to produce the same result during repeated execution. They create predictability during failure when combined with controlled recovery features. Systems that often complete work needs to be trusted.
Race conditions and the illusion of order
The fact that events do not often occur in an expected sequence is an overlooked feature of asynchronous systems. Different processes can communicate using the same data at the same time. Differences in timing create unexpected outcomes that are hardly seen during development, in production workloads. There is no assurance about implementing an order. This means different workers can upload the same data:
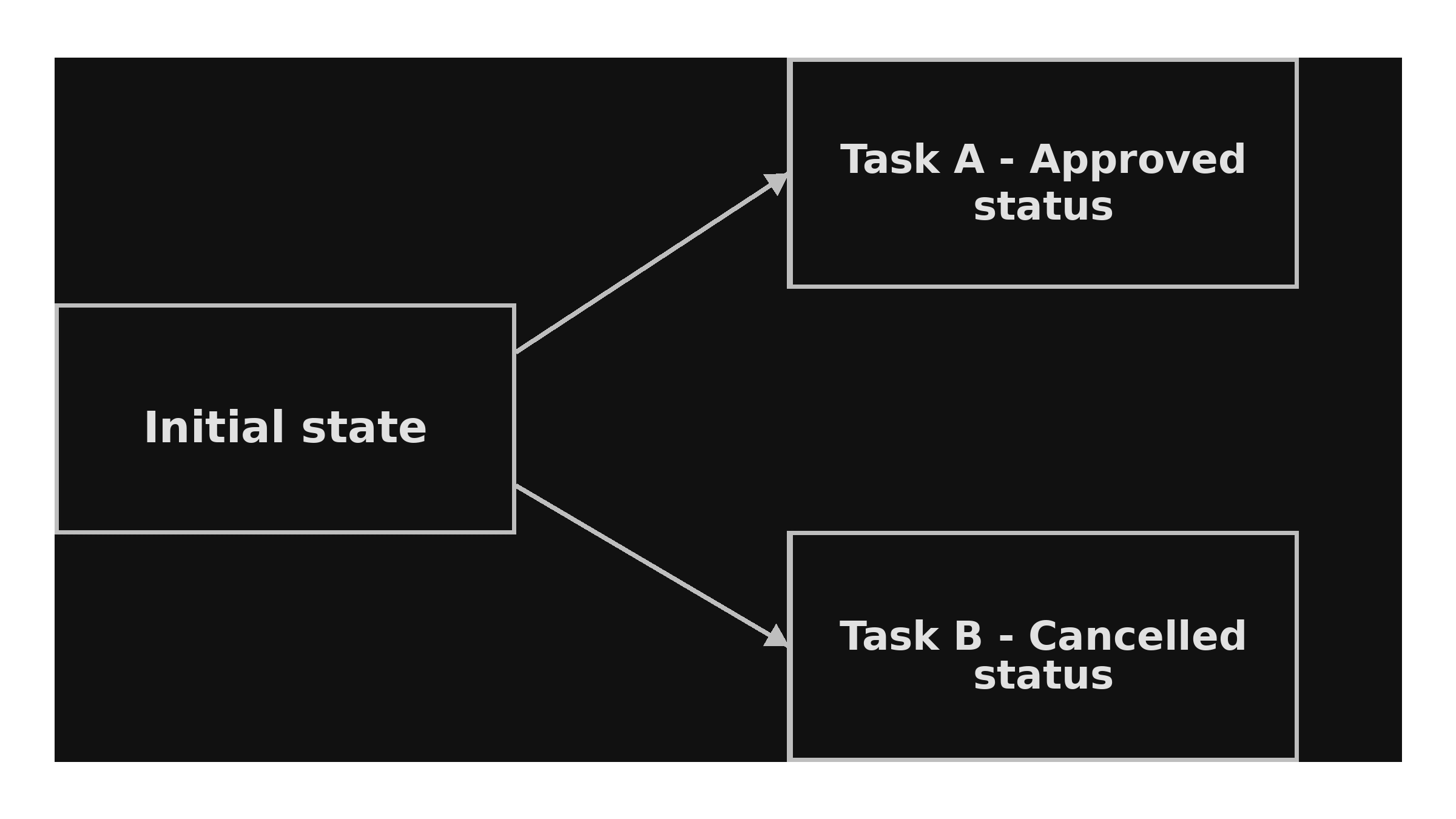
I have seen this cause challenges such as missing records. This is why mature platforms handle state management and workflow governance as important system concerns. The aim is not to remove concurrency. It is to produce deterministic outcomes in the workplace.
Debugging without a call stack
Debugging works differently in asynchronous systems. Teams have to reconstruct events in multiple systems and workflows. They do not follow a single operational path.
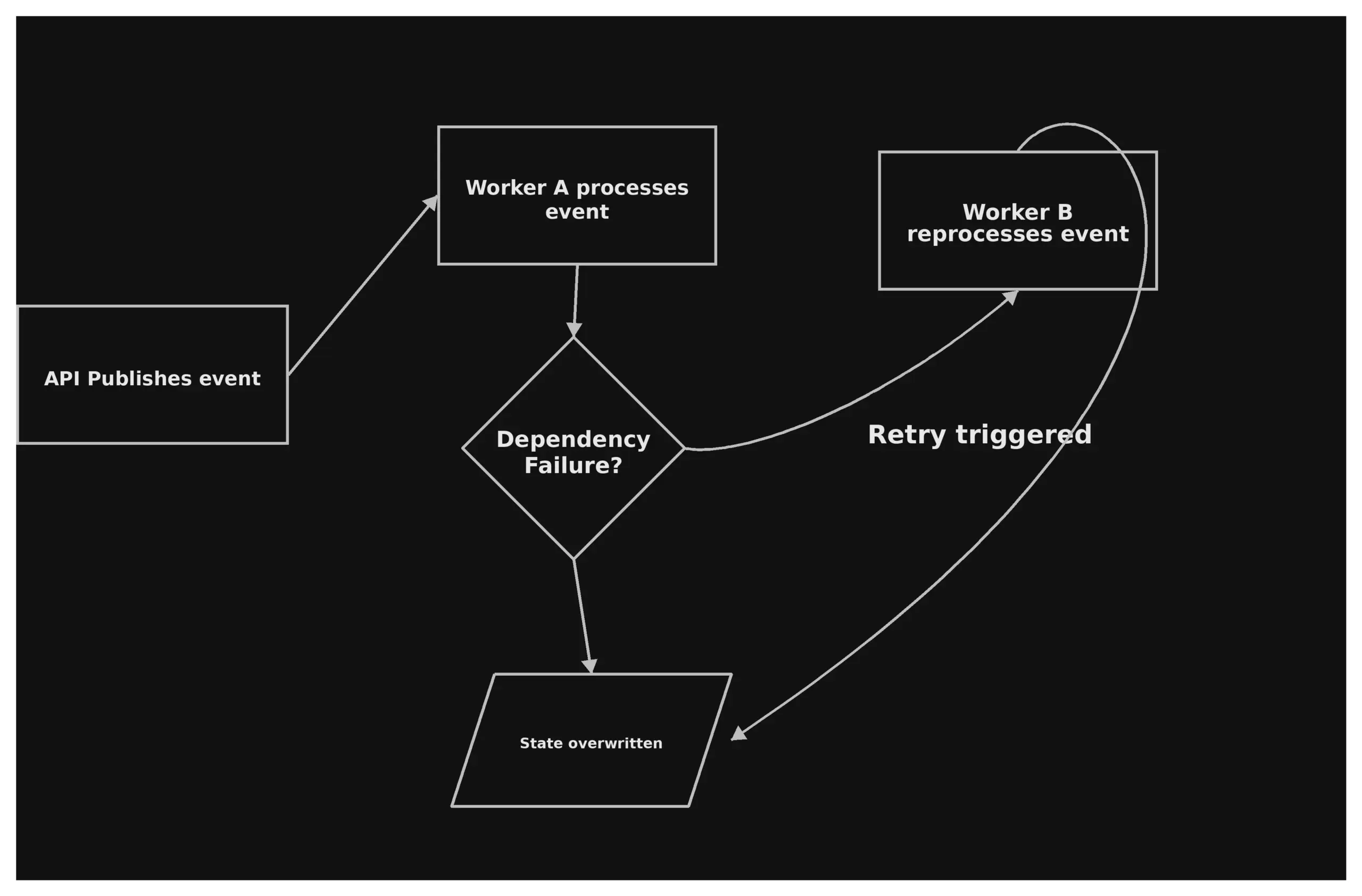
The concern moves from questions like what made this action fail? to what processes produced this outcome? Systems become more distributed, making visibility the first requirement for trust. Monitoring and operational features cease to be optional needs. They become basic capabilities.
A structured model for production async systems
Some organizations manage trust in asynchronous systems reactively. They begin by introducing a queue, then start monitoring the system recovery features, and move to the governance processes after a failure occurs. A deeper insight shows that the most suitable approach is to handle reliability as a coordinated system from the beginning.
The async reliability model
I used a five-structure trusted model based on my experience in building and handling production asynchronous platforms. The following are the models: (1) Typology: this model makes the workflow structure clear and isolates failure. (2) Execution: this layer handles state changes and consistent processing. (3) Retry: this is a recovery feature designed to remain stable even under stress. (4) Visibility: this model handles monitoring and processing insight. (5) Governance: This model explains ownership and management of the lifecycle. Every layer I used handles a different kind of failure and reinforces others. Working together, they produce a trusted model for shared systems.
What the industry can reuse
The importance of this model is that it is not constrained to a particular technology stack. The principles apply whether industries use traditional messaging systems or event-driven systems. Trust is increased when governance and architecture are handled as parts of a single system.
What are the advances in modern distributed systems?
One of the major contributions is a change in perspective. Some industries handle asynchronous systems like performance optimization, yet the real application of these systems shows a trust challenge that demands deliberate design. When workflow structure and governance are incorporated into a unified model, teams can reduce system inconsistency before failures occur.
Async is an architectural commitment
The growth of Asynchronous platforms was very gradual because each edition looked small in isolation. When combined, these decisions change an application into a shared system with different trust requirements. Systems with the highest tools are hardly the most resilient. The best systems are those whose teams acknowledge that trust must be implemented into the system from the start.
Asynchronous operation provides important scalability advantages and is more than a performance feature. This means that it is committed to managing uncertainties in operations and system reliability. The existence of asynchronous platforms is not the cause of the failure in async systems. The failure occurs when trust is not treated as a design principle.